
داده کاوی چیست
داده کاوی به معنی پیدا کردن الگو حاکم بین عناصر در داخل مجموعه دادههای بزرگ می باشد. به زبان سادهتر، داده کاوی فرایند استخراج دادههای قابل استفاده از بین حجم عظیمی از دادههای خام می باشد. در data mining، الگوی بین دادهها توسط چندین نرم افزار تجزیه و تحلیل میشود. در ادامه با انواع الگوریتم های داده کاوی آشنا خواهید شد.
الگوریتم داده کاوی به یک سری روشهای اکتشافی و محاسباتی گفته میشود که هدف آنها ایجاد یک مدل از داده های مورد نظر است. برای ایجاد یک مدل، ابتدا داده ها برای یافتن نوعی الگو یا رویکرد توسط الگوریتم تحلیل می شود.
سپس الگوریتم با اعمال نتیجه حاصل از این تحلیل بر روی نمونهها، بهینه ترین پارامترها را یافته و یک مدل ایجاد میکند. سپس این پارامترها بر روی مجموعه دادهها اعمال شده و یک الگوی کاربردی به دست میآید.

داده کاوی کاربرد های زیادی دارد که شامل کمک به تحقیقات و علوم پایه نیز میشود. با استفاده از نتایج این محاسبات، شرکتها میتوانند مشتریان خود را بیشتر شناخته و با استفاده از اطلاعات بدست آمده تدابیر لازم را جهت افزایش سود یا جلوگیری از هر گونه ضرری، اتخاذ کنند.

با این کار شرکتها سریعتر به اهداف خود دست پیدا کرده و تصمیمات بهتری میگیرند. داده کاوی شامل جمع آوری موثر داده از مشتریان، موجودی انبار و اطلاعاتی از این دست میشود.
خصوصیات اصلی داده کاوی
- پیشبینی خودکار الگوها با توجه به تحلیل روند و رفتار
- پیشبینی بر اساس خروجیهای احتمالی
- ایجاد اطلاعات مبتنی بر تصمیم
- تمرکز بر روی مجموعه دادههای عظیم و پر حجم
- خوشه بندی داده ها بر اساس یافتهها و حقایق بصری نا آشنا
اهمیت استفاده از داده کاوی
با توجه به اینکه مقدار دادههای تحلیل نشده هر دو سال یکبار، دو برابر میشود و 90% از دادههای دیجیتالی موجود را دادههای غیر سازمان یافته تشکیل میدهد، برای تجزیه و تحلیل این حجم از اطلاعات به یک سیستم منسجم و موثر نیاز است.
به عبارت دیگر اطلاعات بیشتر به معنی دانش بیشتر نیست. اینجا است که داده کاوی مطرح میشود:
- با کمک داده کاوی میتوان هرگونه تغییری را در میان داده های نویزی و تکراری، کشف کرد.
- میتوان نکات مهم و تاثیرگذار در یک خروجی بهینه را پیدا کرده و با استفاده از این اطلاعات به نتایج بهتری دست یافت.
- میتوان فرایند تصمیمگیری مبتنی بر دانش را سرعت بخشید.
با وجود اینکه تحلیل پیشگویانه از مدتها پیش در علوم پایه مطرح بوده اما تکنولوژی لازم برای استفاده از آن در دسترس نبود. اما با توجه به پیشرفتهای بشری، اکنون زمان استفاده از آن فرا رسیده است.

با گذر زمان، شرکتها و سازمانهای بیشتری به اهمیت استفاده از تحلیل پیشگویانه پی میبرند. این قبیل شرکت ها اهداف خود را بر این اساس تنظیم کرده و با استفاده از همین تکنیکها از رقبای خود پیشی میگیرند. یکی از تکنیکهایی که در تحلیل پیشگویانه مورد استفاده قرار میگیرد، داده کاوی است.
انتخاب الگوریتم های داده کاوی مناسب
انتخاب الگوریتم داده کاوی مناسب برای تحلیل داده های به خصوص، کاری چالشبرانگیز است. می توان برای تحلیل یک نوع داده از چند نوع از الگوریتم های داده کاوی استفاده کرد، اما نتایج حاصل از آنها با یکدیگر متفاوت خواهد بود.
برای مثال با استفاده از الگوریتم درخت تصمیمگیری مایکروسافت میتوان نتایج را پیشبینی کرد، اما در عین حال میتوان از آن برای حذف یا کاهش تعداد ستونهای موجود در دیتاست نیز استفاده کرد. چرا که این الگوریتم میتواند ستونهایی که در نتیجه نهایی تاثیری ندارند را تشخیص دهد.
الگوریتم های دسته بندی (Segmentation algorithms)
برای یافتن نتیجه یک یا چند متغیر مجزا بر اساس خصوصیات دیتاست، مورد استفاده قرار میگیرد.
الگوریتم های رگرسیون
برای پیشبینی یک یا چند متغیر عددی، مثل سود یا ضرر، به کار میرود.
الگوریتم های خوشه بندی
عناصر موجود در data set را بر اساس تشابهات آنها در گروه یا خوشه قرار میکند.
الگوریتم های وابستگی (Association algorithms)
برای پیدا کردن رابطه بین خصوصیات مختلف عناصر دیتاست به کار میرود. متداولترین اپلیکیشنهایی که با این الگوریتم طراحی میشوند به قانون وابستگی شهرت دارند که برای تحلیل جذابیت بازار مورد استفاده قرار میگیرند.
الگوریتم های تحلیل زنجیره ای (Sequence analysis algorithms)
از توالی یا اتفاقات مکرر در بین عناصر data set، یک خلاصه ایجاد میکند. مثل کلیک های صورت گرفته در یک وب سایت.
انواع الگوریتم های داده کاوی
الگوریتم C 4.5: یکی از الگوریتم های داده کاوی الگوریتم های طبقه بندی است که با استفاده از درخت تصمیم گیری یک جدا کننده ایجاد می کند. برای این کار از دیتا ستی که قبلا دستهبندی شده، استفاده میشود. این الگوریتم داده کاوی که به الگوریتم دستهبندی آماری نیز معروف است که در اصل حالت توسعه یافته الگوریتم ID3 است.
درخت تصمیمگیری ایجاد شده توسط الگوریتم C 4.5 را میتوان برای دستهبندی دادهها استفاده کرد. به گفته سازندگان نرم افزار یادگیری ماشین وکا، این الگوریتم برجستهترین درخت تصمیمگیری بوده و اصلی ترین و پرکاربردترین روشی است که تا به امروز برای یادگیری ماشین کشف شده است.
الگوریتم K-means
این الگوریتم که به دستهبندی کننده نزدیکترین عنصر به مرکز نیز معروف است، روشی برای ارزیابی بردار بوده که در بین الگوریتم های خوشه بندی از محبوبیت زیادی برخوردار است.
با این الگوریتم، می توان عناصر دیتاست را در K گروه دسته بندی کرد که در هر دسته عناصری با خصوصیات مشابه قرار دارند. الگوریتم K-means یکی از پرکاربرد ترین الگوریتم هایی است که برای تحلیل خوشه ای و کاوش یک دیتا ست، مورد استفاده قرار می گیرد.
الگوریتم Support vector machines
در بحث یادگیری ماشین، Support vector machines که به شبکه Support vector نیز معروف است، یکی از روشهای یادگیری نظارت شده محسوب می شود که به همراه الگوریتم های یادگیری وابسته، دادهها را تحلیل می کنند. سپس این داده ها در تحلیل رگرسیون یا دستهبندی مورد استفاده قرار میگیرند.
مدل ایجاد شده توسط SVM همانند نمودی از نقطههای نمونه در فضا هستند که عناصر مشابه در کنار هم و عناصر متفاوت با نقاط دورتر مشخص میشوند.
الگوریتم Apriori
این الگوریتم برای داده کاوی مکرر و یادگیری قانون وابستگی بر روی بانکهای اطلاعاتی کلی، مورد استفاده قرار میگیرد. در این الگوریتم ابتدا عناصری که به صورت مکرر در دیتاست مشاهده میشود، شناسایی میشود. سپس آن را با عناصر دیگری که به اندازه کافی در دیتاست تکرار شدهاند، گسترش میدهد. پس از اینکه عناصر تکرارشونده توسط این الگوریتم تعیین شد، می توان از آنها برای وضع قوانین وابستگی که نشاندهنده روندهای اصلی است، استفاده کرد.
الگوریتم Expectation Maximization یا EM
الگوریتم Expectation Maximization در تحلیلهای آماری مورد استفاده قرار میگیرد. کاربر آن در تخمین حداکثر احتمال درستی پارامتهای یک مدل آماری است.
الگوریتم Page rank
این الگوریتم که به افتخار لری پیج، یکی از بنیانگذاران گوگل نامگذاری شده، برای رتبهدهی به وب سایتها در موتور جستجوگر گوگل مورد استفاده قرار گیرد. الگوریتم Page Rank تنها الگوریتم مورد استفاده شرکت گوگل برای رتبهدهی نیست اما بهترین روش برای ارزیابی اهمیت یک وب سایت میباشد.
الگوریتم AdaBoost
تقویتکننده تطبیقی که به AdaBoost نیز معروف است، توسط یوو فروند و رابرت شاپیر توسعه داده شده است. این الگوریتم یادگیری ماشین است در سال 2003 برنده جایزه گودل شد. نکته جالب در مورد این الگوریتم امکان استفاده آن در ترکیب با دیگر الگوریتمهای یادگیری است. AdaBoost به دادههای نویزی و پرت حساس است.
الگوریتم k-nearest neighbors
این الگوریتم داده کاوی، جزو الگوریتم های یادگیری تنبل یا یادگیری مبتنی بر مثال بوده و روشی غیرپارامتری است. از این الگوریتم در دستهبندی و رگرسیون استفاده میشود. در هر دو روش یادگیری، ورودی شامل K نمونه آموزشی نزدیک (از نظر خصوصیات فضا) میباشد و خروجی آن به الگوریتمی که برای دستهبندی یا رگرسیون استفاده شده، بستگی دارد. روش KNN سادهترین الگوریتم در بین الگوریتم های یادگیری ماشین است.
الگوریتم Naive bayse
الگوریتم Naive bayse جزو الگوریتم های طبقه بندی احتمالی ساده بوده و بسیار مقیاسپذیر است. این الگوریتم بر اساس تئوری بیز و با استفاده از فرضیههای مستقل قدرتمندی که بین خصوصیات مختلف وجود دارد، کار می کند.
الگوریتم CART
کلمه کارت مخفف عبارت درخت های طبقه بندی و رگرسیون میباشد. این الگوریتم یک روش یادگیری مبتنی بر درخت تصمیمگیری است که خروجی آن درخت تصمیم گیری طبقهبندی کننده یا درخت تصمیمگیری رگرسیون میباشد و همانند الگوریتم C 4.5 جزو الگوریتم های دستهبندی محسوب میشود.
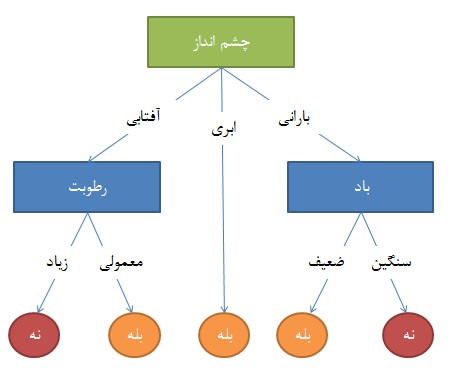
از آنجایی که هر دو الگوریتم فوق از درخت تصمیم گیری استفاده می کنند، اغلب کاربرانی که از الگوریتم C 4.5 استفاده می کنند، الگوریتم Cart را هم روی داده ها آزمایش می کنند.




