آموزش خوشهبندی در متلب با هدف تجزیه و تحلیل مجموعه دادهها برای یافتن الگوهای پنهان یا گروهبندی آنها انجام میشود. این الگوریتم در آنالیز داده و کشف اطلاعات پنهان، تشخیص و شناسایی ناهنجاریهای موجود در دادهها و پیش پردازش یادگیری با نظارت در هوش مصنوعی کاربردهای فراوانی دارد. الگوریتم خوشهبندی یکی از الگوریتمهای پرکاربرد در متلب هست. برای آشنایی بیشتر با مفهوم خوشهبندی در متلب ادامه این نوشته را از دست ندهید.
الگوریتم خوشه بندی در متلب چیست؟
الگوریتم خوشهبندی در متلب دادههای موجود در یک گروه «خوشه یا کلاستر» را با خوشههای دیگر مقایسه کرده و بیشترین تشابه را میان آنها پیدا میکند. در نتیجه دادههایی مشابه در یک خوشه قرار میگیرند که الگوی مشترک آنها کشف میشود. تکنیکهای ریاضی زیادی برای کشف تشابه میان خوشهها میتوان مورد استفاده قرار داد، که فاصله اقلیدسی، احتمالات، فاصله کسینوسی و همبستگی معروفترین آنها هستند.

الگوریتمهای خوشهبندی را میتوان در دو گروه دستهبندی کرد.
- خوشهبندی سخت «Hard clustering»: در این نوع الگوریتم خوشه بندی در متلب هر نقطه تنها به یک خوشه تعلق دارد. الگوریتم کامینز «K means» زیر مجموعه این گروه محسوب میشود.
- خوشهبندی نرم «Soft clustering»: در خوشهبندی نرم هر نقطه میتواند به بیش از یک خوشه تعلق داشته باشد. بهعنوانمثال ژنهایی که در فرایندهای بیولوژیک متعددی دخیل هستند.

تصویر ۱- شمای مفهومی پیاده سازی الگوریتم k means. هر نقطه تنها در یک خوشه عضو است.

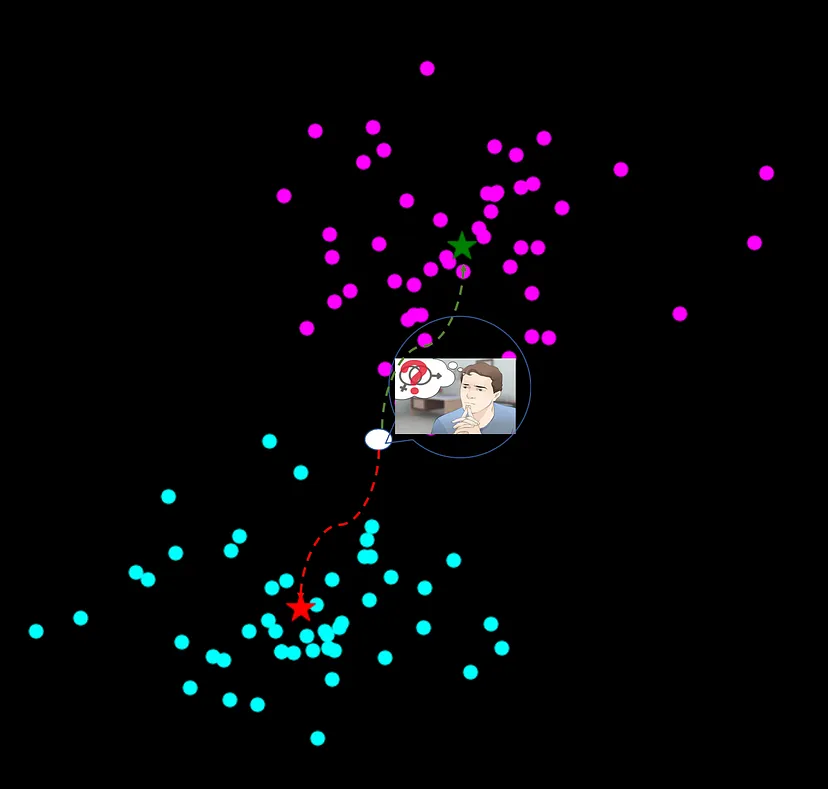
تصویر ۲- الگوریتم مخلوط گاوسی، که احتمال عضویت نقاط در خوشهها را تعیین می کند که نشان دهنده قدرت ارتباط با خوشههای مختلف است.
کاربردهای الگوریتم خوشهبندی
الگوریتم خوشه بندی در متلب کاربردهای مختلفی دارد. برخی از حوزههای پرکاربرد این نوع الگوریتمها به شرح زیر هستند:
- خوشهبندی سیگنالهای خطی خام برای فشردهسازی دادهها.
- خوشهبندی مناطق مختلف یک تصویر برای پردازش آن.
- خوشهبندی توالی ژنتیکی در بیوانفورماتیک.
از تکنیکهای خوشهبندی برای تشخیص شباهت میان دادههای برچسبدار و بدون برچسب در یادگیری نیمه نظارتی نیز استفاده میشود. در حقیقت از الگوریتم خوشهبندی برای شناسایی دادههای بدون لیبل که باید دارای لیبل باشند کمک میگیریم. نرمافزار متلب بسیاری از الگوریتمهای خوشهبندی را پشتیبانی میکند. برای آشنایی بهتر با این مبحث به آموزش خوشهبندی k means در متلب که در ادامه میخوانید توجه کنید.
پیشنهاد مطالعه: کتاب آموزش متلب – ۱۲ کتاب آموزشی برتر فارسی و انگلیسی
الگوریتم خوشهبندی کامینز چیست؟
برای درک بهتر خوشهبندی کامینز یک مثال ساده در نظر داریم. فرض کنید عدهای میخواهند فوتبال بازی کنند. ابتدا باید تعداد تیمها مشخص شود. بعد به تعداد تیم کاپیتان انتخاب میکنیم. سپس کاپیتانها باید با توجه به معیارهایی که در ذهن خود دارند و با توجه به شناختی که از هر بازیکن دارند تیم خود را انتخاب کنند. اما در این مثال قوانین انتخاب هم تیمی را کمی تغییر میدهیم. هر کاپیتان باید افرادی را انتخاب کند که در نزدیکترین فاصله با او ایستاده باشند. منظور از فاصله شباهت میان کاپیتان و بازیکن مورد نظر هست.
طبق مثال فوق قدم اول تعیین تعداد تیمها است. در الگوریتم k means به این مرحله تعیین تعداد خوشه گفته میشود. خوشه را با حرف k نشان میدهیم؛ بنابراین اگر تعداد خوشهها ۳ باشد k=3 را داریم. تعداد خوشه توسط کاربر مشخص میشود.
مرحله بعدی به انتخاب کاپیتان اختصاص پیدا میکند. در الگوریتم کامینز این عملیات را تعیین مراکز خوشهها مینامیم. مرکز یک خوشه مرجع، کاپیتان یا نماینده آن خوشه است. مرجعی که طبق تابع هدف با دیگر اعضا مقایسه میشود. حال هر کاپیتان باید معیارهای خود را مورد سنجش قرار داده و مطابق آنها نزدیکترین بازیکنان به خود را انتخاب کند. در خوشهبندی کامینز در متلب این مرحله فاصله سنجی نام دارد. یعنی هر نماینده باید دادههای نزدیک به خود را به عنوان یک شاخه از خوشه خود ثبت کند. در واقع فاصله تمام دادهها با هر کدام از مراکز خوشه بررسی و تعیین میشود. کمترین فاصله یعنی بیشتر تشابه.
مرحله آخر مثال ما یارکشی توسط کاپیتان برای تیم است. در کامینز این مرحله را خوشهبندی مینامیم. یعنی نقاط نزدیک به هر مرکز خوشه عضو آن خوشه میشود.

تصویر بالا یک مثال ساده برای نمایش نحوه عملکرد این الگوریتم است. اما میخواهیم مثال خود را تکمیل کنیم. فرض کنید تعداد افرادی که در تیمها حضور دارند برابر نیست که یک خطای محاسباتی محسوب میشود. چون اعضای تیم بر اساس فاصلهشان تا کاپیتان انتخاب شدهاند؛ بنابراین یا باید خود کاپیتانها را عوض کنیم یا جای آنها را. بهترین انتخاب جابجا شدن کاپیتانها خواهد بود.
در الگوریتم کامینز به این جابهجایی بهروزرسانی مرکز خوشه میگوییم. به این معنی که با توجه به اطلاعات به دست آمده از مرحله قبلی خوشهبندی معیارهای انتخاب زیر مجموعه تغییر پیدا میکنند. این فرایند آنقدر تکرار خواهد شد که بهترین موقعیت برای مراکز خوشهها پیدا شود. بهترین موقعیت یعنی کمترین میزان خطا که همان صفر است.

آموزش الگوریتم خوشهبندی k means در متلب
برای پیادهسازی کد متلب الگوریتم k means میتوانید از فلوچارت زیر استفاده کنید.

طبق فلوچارت بالا تا زمانی که خوشهبندی به مینیموم خطا برسد حلقه متوقف نخواهد شد. اما اگر به این نقطه برسیم فرایند خوشهبندی نیز به اتمام میرسد. فرمول ریاضی الگوریتم خوشهبندی کامینز در متلب به شکل زیر است.

کلام آخر
خوشه بندی در متلب یکی از مباحث مهم در علوم داده محسوب میشود. نرمافزار متلب نیز به عنوان یکی از ابزارهای کارآمد در پیادهسازی الگوریتمهای خوشهبندی است. در این مقاله امکان پیادهسازی الگوریتمهای خوشهبندی در متلب را مورد بررسی قرار دادیم. اما به دلیل تخصصی بودن موضوع نتوانستیم به طور دقیق روش پیادهسازی کد آن در متلب را آموزش دهیم. از این جهت پیشنهاد میکنیم در صورت تمایل به یادگیری، به رسانه آموزش مجازی مکتب خونه مراجعه کنید و دورههای آموزش متلب را ببینید.






